Semestrální projekt PAR 2004/2005:
Paralelní algoritmus pro řešení problému:
Pokrývání plochy obdélníky (Úloha POO)
Václav Ševčík, Jindřich Gottwald
5. ročník, obor počítače, K336 FEL ČVUT, Karlovo nám. 13, 121 35 Praha 2
6.1.2005
1. Definice problému a popis sekvenčního algoritmu
1.1 Vstupní data:
A = obdélníková síť o rozměrech a, b >= 5
B[1..3] = množina 3 obdelníkových tvarů písmen o velikostech 3x3, 2x4, 1x5
1.2 Úkol:
Pro zadanou síť A o velikosti a x b nalezněte její vyplnění obdélníky z množiny B tak,
aby zůstalo co nejméně nevyplněných políček (v ideálním případě vyplníte celou plochu A)
a přitom každý typ obdélníku je ve vyplnění obsažen alespoň jednou.
Obdélníky můžete při vyplňování otáčet.
1.3 Výstup algoritmu:
Popis vyplnění obdélníku a x b (např. matici a x b znaků, kde každý obdélník je určen
množinou stejných znaků), případně grafické znázornění řešení a nebo výpis, že pokrytí
neexistuje.
1.4 Sekvenční algoritmus:
Sekvenční algoritmus je BB-DFS s hloubkou prohledávaného prostoru omezenou na ab.
Přípustný koncový stav je situace, kdy již nejsme schopni do sítě A vložit další obdélník.
Cenou, kterou minimalizujeme, je počet zbývajících nevykrytých políček. V koncovém stavu
musíme aktualizovat cenu nejlepšího řešení, pokud je cena nalezeného řešení lepší než do té
doby nejlepší známá cena. Algoritmus končí, když každá velikost obdélníka je alespoň jednou
v ploše A použita a cena řešení koncového stavu je rovna minimální možné ceně (tj. nezbyvá
žádné nevyplněné políčko), jinak algoritmus prohledá celý stavový prostor a na konci vypíše
cenu do té doby nejlepšího řešení.
1.5 Popis sekvenčního algoritmu
Cena řešení je brána jako počet nepokrytých políček (obsah) S. Minimální možná cena je S=0.
Pokud tento stav neexistuje, jsou projety všechny možné kombinace. Toto je zřejmá nevýhoda
algoritmu. Za koncový stav je považován každý, který má S<5, tedy jehož volná část je menší
než obsah nejmenšího vkládaného prvku.
Pro zjednodušení testu, kam na plochu uložit další prvek jsou prvky uloženy jako bitové mapy.
Structy ukládány na zásobník mají tento tvar:
int a,b; // rozměry pole
int test; // číslo posledního testovaného prvku
int x,y; // souřadnice na které se chtělo naposedy zapsat
int cislo; // poslední označení uloženého prvku v poli
int obsah; // kolik ještě zbývá obsahu
int typy[typu]; // kolik je v poli obsazených jednotlivých druhů prvků
int *pole; // to nejdůležitějíší - pole obsazenosti
1.6 Vstupy a výstupy programu
Jako vstupní parametr se udává jen rozměr pole - dvě souřadnice odděleny mezerou.
Případně název souboru ve kterém je rozměr uložen.
Výstupem je textový soubor obsahující výsledné pole. Jednotlivé prvky jsou v poli rozlišeny čísly.
Číslo 0 znamená neobsazené pole.
1.7 Tabulka naměřených časů
| rozměr |
5 x 5 |
6 x 7 |
7 x 7 |
8 x 8 |
8 x 9 |
9 x 9 |
| čas [s] |
0.001 |
3.421 |
29.351 |
375,891 |
682,286 |
1422,567 |
2. Popis paralelního algoritmu a jeho implementace v MPI
2.1 Paralelní algoritmus:
Paralelní algoritmus je typu G-PBB-DFS-D, hledání dárce algoritmem GCZ-AHD,
dělení zásobníku pomocí R-ADZ.
Na následujicích řádcích se pokusíme tyto pojmy vysvětlit a popsat jejich implementaci.
Globální paralelní BB-DFS s prohledáváním DDE stavového prostoru G-PBB-DFS-D
Všechny procesory vědí nebo se dozvědí počáteční hodnotu horní i dolní meze ceny řešení.
Každý procesor, který nalezne lepší řešení než jemu známé nejlepší řešení, neaktualizauje pouze
svou informaci, ale rozešle zprávu typu jeden-všem ostatním procesorům, kteří si nastaví
informaci o dosud nejlepším řešení. Je-li to optimální řešení, pak opět dojde k ukončení
výpočtu. Jinak proběhne po vyprázdnění všech zásobníků distribuované ukončení výpočtu pomocí
algoritmu ADUV bez nutnosti následné redukce lokalních řešení. V porovnání s lokální strategií
vede tato strategie k vyšší komunikační režii, ale zase dovoluje eliminovat prohledávání větší
části stavového prostoru, protože každý procesor zná momentálně nejlepší globální řešení a
častěji pozná zbytečnost prohledávání v podprostorech.
DODELAT konkretni implementaci
Hledání dárce algoritmem globální cyklické žádosti GCZ-AHD
Procesor P1 centrálně udržuje globální čítač D. Kdykoli nějaký procesor potřebuje práci,
požádá procesor P1 o aktuální hodnotu D. P1 poté inkrementuje D modulo p.
DODELAT konkretni implementaci
Dělení zásobníku metodou R-ADZ
Zásobník je zobrazen obráceně, dno nahoře, vrchol dole, v souladu s odpovídajícím stavovým stromem.
Má-li dárce za úkol rozdělit svůj zásobník na k+1 částí, kde k je počet žadatelů o práci v
jeho frontě, pak provede dělení na nejbližší možné 1/2i-tiny
opakovaným dělením zásobníku na poloviny (i je horní celá část z log2 (k+1)). Přestože
není velikost stavového prostoru skrývajícího se za nerozvinutými stavy zásobníku odhadnutelná,
předpokládáme, že podprostory jsou tím vétší, čím je neexpandovaný stav blíže dnu zásobníku. Pro danou
úlohu je třeba stanovit práh řezné výšky H, což je maximální výška zásobníku, do které se bude dělení
provádět. Tuto výšku je pro danou úlohu nutno stanovit experimentálně jako funkci velikosti vstupních
dat. Čili dělení se neprovádí, pokud by dělením vznikl zásobník pouze se stavy ve výšce větší než H.
Není-li dárce schopen nalézt dost práce pro všech k čekajících žadatelů, uspokojí pouze první část a
zbytek odmítne. Žadatel obdrží polovinu stavu z výšky H či menší.
DODELAT konkretni implementaci
Algoritmus pro ukončení výpočtu ADUV
DODELAT konkretni implementaci
Hlavní smyčka
Hlavní smyčka algoritmu je tvořena dvěma částmi. V první jsou ...
DODELAT konkretni implementaci
Zásobník
Oproti zásobníku použitém v sekvenčním řešení bylo potřeba doplnit několik funkcí:
bool PopRV(Prvek &p, int rv); // nalezne poslední vložený prvek který má řeznou výšku=rv
int ItemsOnRV(int rv); // spočítá kolik je na zásobníku uložených prvků se zadanou řeznou výškou
2.2 Spouštění programu
Spuštění programu: mpirun -np 'počet procesorů' ./par-sek
DODELAT je to spravne?
3. Naměřené výsledky a vyhodnocení
3.1 Naměřené hodnoty
Řeznou výšku jsme testováním stanovili jako 2*rozměr.a*rozměr.b/15. Dále jsme testováním
určily vhodné soubory vstupních dat, pro které je časová složitost sekvenčního algoritmu
řádu minut, nejvíce pak 30 minut. Jako mezní rozměr jsme použili 9 x 9, kdy sekvenční
řešení trvá asi 24 minut. Měření jsme provedli na 2, 4, 8 a 12ti procesorech svazku star.
K měření času jsem využívali knihovní funkci MPI_Wtime, která vrací časové razítko.
Pomocí dvou časových razítek na začátku a na konci paralelního řešení jsme získali čas
běhu aplikace mezi těmito razítky.
| rozměr |
čas [s] |
1 proces |
2 procesy |
4 procesy |
8 procesů |
12 procesů |
| 8 x 8 |
t1 |
|
215,25 |
121,12 |
75,87 |
48,68 |
| t2 |
|
217,42 |
121,11 |
75,65 |
47,52 |
| t3 |
|
215,43 |
121,92 |
76,93 |
48,16 |
| tprům |
375,89 |
216,03 |
121,38 |
76,15 |
48,12 |
| 8 x 9 |
t1 |
|
382,14 |
217,11 |
129,65 |
92,48 |
| t2 |
|
381,53 |
217,15 |
129,40 |
93,02 |
| t3 |
|
382,62 |
216,85 |
129,49 |
93,40 |
| tprům |
682,29 |
382,10 |
217,04 |
129,51 |
92,97 |
| 9 x 9 |
t1 |
|
852,98 |
499,45 |
275,22 |
153,85 |
| t2 |
|
853,12 |
501,12 |
275,97 |
154,69 |
| t3 |
|
853,22 |
499,65 |
274,10 |
153,23 |
| tprům |
1422,57 |
853,11 |
500,07 |
275,10 |
153,92 |
3.2 Zrychlení a efektivnost
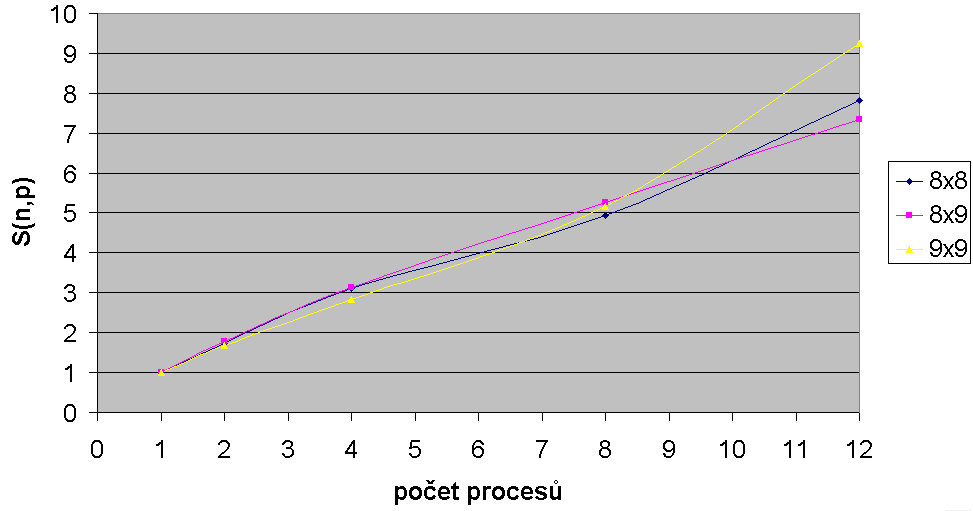
Z naměřených dat jsme sestavili následují tabulku zrychlení S(n,p).
Zrychlení S(n,p) jsme zjistili podle vztahu:
kde SU(n) je sekvenční složitost problému a T(n,p) je paralelní čas.
Tabulka a graf pro zrychlení pak vypadají takto:
| rozměr |
1 proces |
2 procesy |
4 procesy |
8 procesů |
12 procesů |
| 8 x 8 |
1,00 |
1,74 |
3,10 |
4,94 |
7,81 |
| 8 x 9 |
1,00 |
1,79 |
3,14 |
5,27 |
7,34 |
| 9 x 9 |
1,00 |
1,67 |
2,84 |
5,17 |
9,24 |
Efektivnost E(n,p) jsme vypočítaly podle vztahu:
a z naměřených hodnot jsme sestavili následují tabulku efektivnosti E(n,p):
| rozměr |
1 proces |
2 procesy |
4 procesy |
8 procesů |
12 procesů |
| 8 x 8 |
1,00 |
0,87 |
0,78 |
0,62 |
0,65 |
| 8 x 9 |
1,00 |
0,89 |
0,79 |
0,66 |
0,62 |
| 9 x 9 |
1,00 |
0,84 |
0,71 |
0,65 |
0,77 |
3.3 Závěr
Z grafu zrychlení je vidět, že ani jedna ze závislostí není superlineární (S(n,p) není větší než p).
Z tabulky efektivnosti je vidět, že ve většině případů míra efektivnosti s počtem procesů klesá.
Náš předpoklad, že výpočet pro rozměry, které jako řešení zaplní celou plochu, bude znatelně
rychlejší než pro úlohy které toto řešení nemají, se nevyplnil.
Náš algoritmus splnil požadované zadání a žádné další vylepšení nás nenapadá.
4. Literatura
Tvrdík, Pavel, Doc. Ing. CSc., Paralelní systémy a algoritmy, CVUT, Praha, 2002