Itanium:
 | - 64bitový procesor s EPIC architekturou (spojené vlastnosti CISC procesorů s RISC jádrem)
- frekvence 733MHz a 800MHz
- 0,18mikronová technologie
- 32bitový mód pro zpracování starých instrukcí
- predikátování, speculativní provádení, explicitní paralelismus
- registrů: 128 celočíselných, 128 FPU, 64 predication
- superscalární provádení instrukci (až 6 instrukcí v jednom cyklu)
- výkonné jednotky: 4xALU, 2xFPU, 3xBranch unit (vyhodnocení skoků)
- cache: L1 - 32KB; L2 - 96KB; L3 - 2MB, 4MB
|
Slovníček pojmů:
| Merced | - pracovní jméno pro Itanium
|
| EPIC | - Explicilty parallel instruction computing
|
| SIMD | - Single instruction multiply data
|
| ILP | - Instruction level paralelism
|
| ALAT | - Advanced load adress table
|
| VLIW | - Very long instruction word
|
| Třídy instrukcí: |
- logické
- aritmetické
- srovnávací
- posuvy a rotace
- multimediální
- větvení
- větvení řídící vykonání cyklu
- v pohyblivé řádové čárce
- v pohyblivé řádové čárce (SIMD)
- přístup do paměti
- přesunu
- řízení cache
|
| Základní typy instrukcí: |
- instrukce pro práci s pamětí (M)
- instrukce pro práci s celými čísly (I)
- instrukce pro práci v pohyblivé řádové čárce (F)
- funkce zahrnující velké konstanty (L)
- instrukce větvení (B)
|
Syntaxe instrukce: (qp) inst[.comp] dests=srcs
| (qp) | - obsahuje predikátový registr (určuje, zda se instrukce provede nebo se provede jako NOP)
|
| inst | - identifikátor instrukce
|
| comp | - konkrétní varianta instrukce
|
| dests | - seznam cílových operandů (většinou jeden registr)
|
| srcst | - seznam zdrojových operandů (vetšinou dva registry nebo konstanty)
|
Příklady instrukcí:
| add r1 = r2, r3
(p4) sub r1 = r2, r3
and r1 = r2, 1
cmp.eq p1,p2 = r4, r3
|
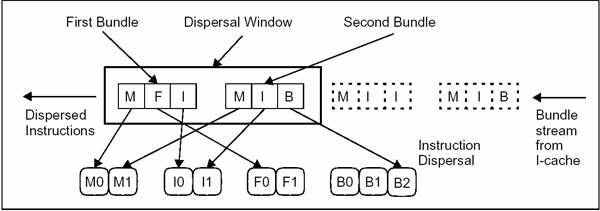
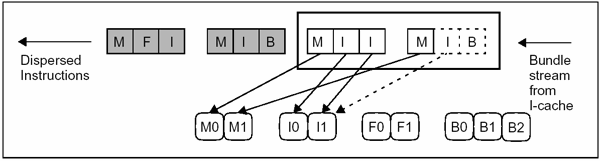
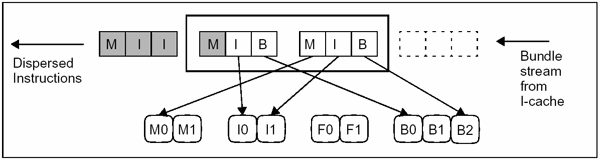
Instrukce: Všechny instrukce jsou umístěny v 128bitových balíčcích (bundles). Balíček tvoří základní prvek pro paralelní zpracování.
Každý balíček obsahuje 3 41bitové instrukce a 5bitovou šablonu (template). Balíček je načten najednou a podle šablony se instrukce namapují do příslušných výkoných jednotek.
Všechny instrukce v balíčku lze provést najednou, protože je provádějí různé funkční jednotky.
Libovolný počet balíčků je seskupen do superbalíčků. Instrukce v každém superbalíčku se navzájem neovlivňují, takže mohou být prováděny paralelně v libovolném pořadí.
Predikace: Moderní procesory se snaží předpovědět správnou cestu.
Předpoví-li ji však špatně, dojde k obrovské ztrátě výkonu. Proto se u Itania používá tzv. predikátování.
Jedná se o paralelní zpracovaní obou možných větví.
Ukažme si vše na příkladu: if (A=1) then DO1 else DO2
Kompilátor převede tuto část nějak takto:
pokud A=1 potvrď[1] jinak potvrď[2]
[1] DO1
[2] DO2
Itanium pak bude pracovat následovně: Na prvním řádku zjistí, že bude pokračovat jednou ze dvou větví.
Začne zpracovávat obě větve současně a zároveň vyhodnocovat podmínku. Ve chvíli, kdy je podmínka vyhodnocena, potvrdí se platnost jedné větve.
Pak se zapíší všechny změny. Itanium může provádět až 64 větví najednou.
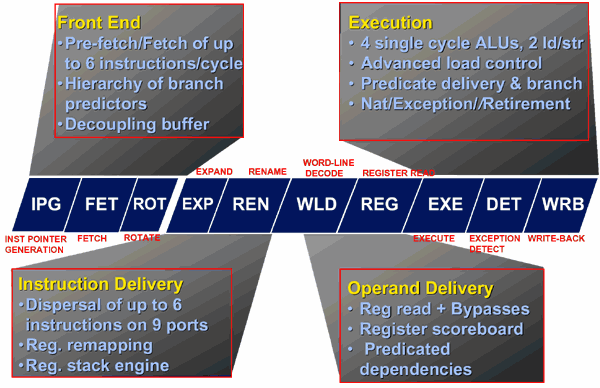
Pipeline: Merced používá desetiúrovňovou pipeline, rozdělenou na dvě části: pipeline pro provádění instrukcí a pipeline pro načítání instrukcí.
Toto rozdělení umožňuje pokračovat v načítání instrukcí i v případě, že výkonná jednotka musí čekat a naopak.
|
IPG
FET
ROT
.....
EXP
REN
WLD
REG
EXE
DET
WRB
| - výběr adresy
- načtení instrukce z instrukční pipeline
- vstup do fronty instrukcí
- instrukce je ve frontě
- vstup do instrukční jednotky
- přemapování registrů
- začátek přístupu do souboru registrů
- přístup k souboru registrů
- provedení instrukce
- detekce vyjímek
- zpětný zápis
|
I když Merced neprovádí instrukce mimo pořadí, různé doby provádění instrukcí způsobují dokončení mimo pořadí.
Kvůli tomu je v procesoru umístěn registr scoreboard, který je určen k indikaci, zda je cílový registr používán.
Instrukce tečou v pipeline do doby, kdy nějaká instrukce chce přistoupit k registru,
který je v scoreboardu označen jako nedostupný, pak se tok instrukcí pozastaví.
Merced se snaží uplatňovat ILP, tedy ideu paralelizmu na úrovni zpracování instrukcí.
To znamená v jednom okamžiku zapojit do výpočtu více jednotek, které zpracovávají více instrukcí najednou.
S tím se oběvují problémy při instrukcích větvení a kvůli zpoždění paměti .
Protože neexistují nové explicitně paralelní programovací jazyky, realizace ILP připadá na funkci překladače.
Proto v Mercedu hraje překladač významnou roli při predikátování a spekulativním řízení pro uplatnění ILP.
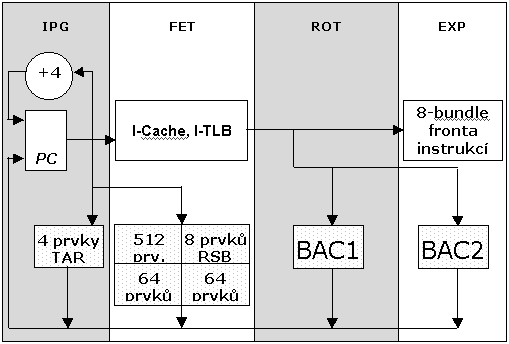
Načítání instrukcí: Předřazená část pipeline se skládá ze tří stupňů. Po výpočtu adresy výběru instrukce v prvním kroku (IPG), přistoupí procesor do instrukční cache v druhém kroku (FET). Ve třetím kroku (ROT) je instrukce zařazena do fronty. Ve frontě může (ale nemusí) instrukce strávit několik taktů a je vyslána do příslušné funkční jednotky (EXP). Přemapování registrů se provádí v dalším kroku (REN) a přístup k velkému souboru registrů (128 položek) vyžaduje dva kroky, které následují (WLD, REN). Nakonec je instrukce vykonána v kroku EXE. Krok DET slouží k přístupu k datům a k dokončování skoků.
Predikce skoku: Chybnou predikcí skoku se ztrácí devět taktů. Proto se musí Merced vyvarovat chyb v predikci skoku za každou cenu. Jednou silnou stránkou IA-64 je, že může odstranit mnoho větvení pomocí predikce, kompletně se vyhýbající možnosti chybné predikce skoku. Merced má implementovány predikční instrukce - BRP - které může překladač využít, aby mohl procesoru pomoci predikovat větvení a určení cílové adresy. Merced je vybaven čtyřmi registry TAR (target adress register), které slouží k uložení cílové adresy posledních BRP instrukcí. Každý TAR rovněž ukládá adresu instrukce větvení. Když program counter (čítač instrukcí) narazí na jednu z těchto adres větvení, je v dalším taktu odpovídající cílová adresa doplněna do instrukční cache. Tudíž až čtyři samostatná větvení mohou pomocí tohoto mechanizmu dosáhnout vykonání během 0 taktů.
Druhá možnost pro přesměrování nebo přemíření větvení se vyskytuje ve druhém kroku (FET). Zde Merced používá další tři predikční mechanismy - 8-položkový návratový zásobník (RSB - return stack buffer) pro predikci návratu z podprogramu, 512-položkovou tabulku historie větvení (BHT - branch history table) a 64-položkovou cache cílových adres větvení (BTAC - branch target adress cache).
Na rozdíl od klasických RISC a CISC architektur, IA-64 může poskytnout statickou predikční poznámku, která určuje, že se jedná o jednoznačnou predikci a proto ji není třeba ukládat do BHT. Přesto, že je BHT mnohem menší než např. u 21264 nebo AMD Athlonu, může dosahovat stejné účinnosti, neboť se zaměřuje pouze na větvení, která vyžadují dynamickou predikci skoku. (Poznámka: BHT je paměť přibližně 20kbitů).
Překladač může umísťovat adresy přímo do BTAC pomocí BRP instrukcí. Větvení, které je v BTAC nebo v RSB okamžitě směruje svou cílovou adresu zpět do předřazené části pipeline a vzniká jednotaktová bublina v načítaných instrukcích. Ale dokud má načítání instrukcí náskok před výkonnou částí procesoru, nezpůsobí tato bublina zastavení výkonné části. Pokud BHT predikuje větvení, které ale není v BTAC, musí být později určeno v jedné nebo dvou BAC (branch adress calculators).
Třetí přemíření se vyskytuje ve dvou situacích. BAC1 může vypočítat cílovou adresu větvení ve třetí pozici nebo celého svazku (bundle). Většina specifikací struktury (templates) umisťují větvení do třetí pozice, takže BAC1 zpracuje těchto větvení nejvíce. Pokud větvení nebylo predikováno BHT, BAC použije statickou predikci kódovanou v instrukci větvení. BAC1 také obsahuje logiku, která sleduje registr čítače cyklů (LS) a potlačuje TAR přemíření, když čítač cyklů indikuje konec cyklu. Každý z těchto případů způsobuje dvoutaktovou bublinu. A pro ostatní případy může BAC2 spočítat cílovou adresu větvení kterékoliv pozice, pokud je tato jednotka použita, způsobuje třítaktovou bublinu.
Ve většině případů, tyto bubliny nezastaví výkonnou pipeline, ačkoliv instrukční buffer musí být skoro plný, aby vykryl zřídkakdy se objevující třítaktovou bublinu. Kromě efektu těchto bublin, větvení zastaví výkonnou pipeline pouze při chybné predikci, tzn. když konečný výsledek všech přemíření je shledán nesprávným, je-li už podmínka větvení vyhodnocena v stupni DET.
Fronta instrukcí: Je to vlastně buffer zařazený mezi první (instruction-fetch pipeline) a druhou (execution pipeline) část piplene. Důvodem je, aby každá z těchto částí mohla pracovat i v případě, že zbývající část pipeline právě nepracuje (např. z důvodu predikce skoků, načítání operandů z paměti,…).
U IA-64 je fronta dimenzována na 8 bundlů (tj. svazků instrukcí), resp. na 24 instrukcí. V každém taktu lze z této fronty vybrat současně až 2 bundly.
Vykonávání instrukcí: Instrukce jsou vykonávány v části execution pipeline. Jelikož IA-64 provádí instruction in-order zpracování instrukcí, mohou být instrukce přiřazeny jednotlivým funkčním jednotkám (executive units) k provedení v okamžiku, kdy jsou vybrány z fronty instrukcí - tj. během stupně EXP.
Instruction stream je rozdělen na tzv. instrukční skupiny (instruction groups), což je skupina instrukcí, které nevykazují vzájemnou datovou závislost (data dependency) a mohou být tedy bez jakýchkoliv obav paralelně prováděny. Konec jedné instrukční skupiny je definován v template části bandlů. Pokud instrukce vybrané z fronty instrukcí patří do stejné instrukční skupiny, mohou být přiřazeny funkčním jednotkám (pokud jsou vůbec potřebné jednotky volné) k provádění. Pokud jsou však instrukce z různých instrukčních skupin, jsou instrukce z následující instrukční skupiny pozdrženy do té doby, než je zpracována předchozí instrukční skupina.
Rozdělení instrukcí do funkčních jednotek
Dvojitá rotace svazků
Jednoduchá rotace svazků
Poté, co procesor přiřadí instrukce k provádění funkčním jednotkám, je nutné vybrat operandy pro tyto instrukce a provést případné přejmenování/přemapování (renaming/remapping) registrů (provádí RSE, tj. register stack engine) - to se provádí ve stadiu REN.
Ve stadiu WLD jsou načteny obsahy příslušných (nyní již přejmenovaných) registrů a v části EXE je instrukce provedena. V části DET se zpracovávají případné výjimky a kontroluje se též chybná predikce skoku (misprediction). Poslední fáze (WRB) zapisuje výsledky instrukce.
Práce s registry:Architektura IA-64 disponuje obrovským množstvím registrů (jednotlivé skupiny registrů jsou pak označovány jako register file).
| Typ registru | Označení | Počet | Rozsah (bitů) | Typ ukládaných dat
|
| General purpose | GR | 128 | 64+1(NaT) | Interer, logical, multimedia
|
| Floating-point | FR | 128 | 82 | Floating-point, multimedia
|
| Branch | BR | 8 | 64 | Adresy
|
| Predicates | PR | 64 | 1
|
| Application | AR | 128 | 64 | Data pro spec. účely
|
| Instruction pointer | IP | 1 | 64 | Adresa právě prováděného bundlu
|
| User mask | UM | 1 | 6
|
| Current frame marker | CFM | 1 | 38
|
| Performance monitor data | PMD | ? | 64
|
| Processor identification | CPUID | ? | 64
|
Přehled registrů
Popis registrů:
General purpose registers: Tyto registry mají rozsah 65bitů (64-bitů pro data a jeden NaT bit). Jsou dostupné ze všech programových úrovní (privillage levels). NaT (Not a Thing) je speciální jednobitové pole, které se používá pro označení odložených (spekulativních) podmínek.
| -static (GR0-GR31): | -jsou viditelné a společné všem podprogramům. GR0 má trvale hodnotu 0, zápis jakékoli hodnoty způsobí Illegal operation fault. GR8-GR31 v IA32 kompatibilním režimu se používají jako 32bitový integer, segment selector a segment descriptor registry.
|
| -stacked (GR32-GR127): | -každý podprogram zde má vyhrazený blok až 96 registrů, který je lokální pouze pro tuto proceduru. Tento blok se nazývá register stack frame.
|
Floating point registers: IA-64 architektura plně implementuje IEEE 754 standard (tj. formáty single, double a double-extended precision). Použití těchto registrů je zřejmé – operace v plovoucí řádové čárce (normální i SIMD). Jsou dostupné ze všech programových úrovní.
| -static (FR0-FR31): | -FR0, resp. FR1 - má trvale hodnotu 0.0, resp. +1.0; zápis do těchto registrů způsobí Illegal operation fault. FR8 – FR31 - v IA-32 kompatibilním režimu se používají jako 32-bitové floating-point a multimedia registry.
|
| -rotating (FR32-FR127): | -mohou být programově přejmenovány a tak napomoci ke zrychlení provádění cyklů
|
Predikátové registry: Používají se pro uchování hodnot IA64 porovnávacích instrukcí a tyto hodnoty se pak používají v instrukcích zpracovávaných pomocí predikátování. Jsou přípustné ve všech programových úrovních.
| -static (PR0-PR15): | -pokud je PR0 použit jako zdrojový operand, má pevně stanovenu hodnotu „1“. Pokud je použit, jako cílový operand, výsledek takovéto operace se ignoruje.
|
| -rotating (PR16-PR63): | -mohou být programově přejmenovány pro urychlení provádění cyklů
|
Branch registers (registry větvení): Používají se pro uchování informací o větvení programu, specifikují cílové adresy pro tato větvení. Jsou dostupné ze všech programových úrovní.
Instruction pointer: Obsahuje adresy bundlu (tj. struktura obsahující trojici 41-bitových instrukcí), který obsahuje právě prováděné IA-64 instrukce. Je možné přímo číst jeho hodnotu, nelze však přímo modifikovat (automaticky se inkrementuje při provádění instrukcí, nebo se jeho hodnota mění v důsledku větvení). Nejnižší čtveřice bitů je nulová.
Při provádění IA-32 instrukcí obsahuje zero-extended 32-bitovou virtuální adresu.
Current frame marker Popisuje stav současného stack frame. Nelze přímo číst ani zapisovat.
Aplikační registry: Jedné se o registry, které se používají k celé řadě speciálních operací. Např.
kernel regs (AR0-7) - jsou registry pro zprostředkování informací mezi OS a aplikacemi;
previous state function reg (AR64) – obsahuje informace o stavu programu před voláním podprogramu;
loop counter reg (AR65) – používá se pro provádění cyklů, automatická dekrementace.
User mask: Obsahuje informace o způsobu adresace a zarovnání adresovatelných jednotek v paměti, způsob organizace vícebytových jednotek (big-endian, little-endian) a uživatelem definovaných výkonnostních monitorů.
Performance monitor data registryZde se shromažďují informace o provádění instrukcí (jak IA-64, tak IA-32).
Mohou být nastavovány pouze privilegovanými instrukcemi, přístupné (pro čtení) jsou ze všech programových úrovní.
CPU identifikační registry: Jejich počet je větší nebo roven 4. Registry 0-3 obsahují základní informace o procesoru (výrobce, číslo, číslo revize,…).
Práce s registry: Kromě úctyhodného počtu registrů nabízí IA-64 několik mechanismů práce s registry. Jsou to především rotating registers a register stack.
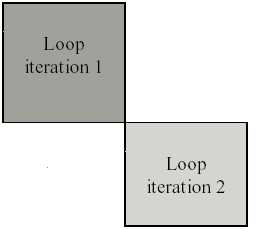
Rotating registers: Umožňuje efektivnější zpracování cyklů. To se může provádět buď sekvenčně nebo paralelně.
 | | 
|
| sekvenční | | paralelní
|
Jedinou překážkou, se kterou se při paralelním zpracování musí systém vyrovnat, je skutečnost, že každá iterace cyklu (loop iteration, průchod cyklem) pracuje se stejnými registry. Systém tedy musí zajistit, aby si dvě iterace stejného cyklu, které jsou vykonávány paralelně, navzájem nepřepisovala data - to zajišťuje tak, že každá z paralelně prováděných iterací pracuje fyzicky s jiným souborem registrů. Tento způsob zpracování cyklů se nazývá loop unrolling.
Základní podmínkou pro takovéto zpracování cyklů je dostatečný počet registrů a nějaký mechanismus, který umožní přiřadit různým iteracím stejného cyklu různé soubory registrů. Většina moderních procesorů používá tzv. přejmenování registrů (renaming registers). Tento mechanismus se implementuje dvěma způsoby: - na úrovni hardwaru - zpravidla poměrně složitá - na úrovni softwaru - v tomto případě loop unrolling provádí kompilátor (zpravidla tak, že několikrát po sobě zopakuje několik iterací cyklu tak, aby se tyto mohly zpracovávat paralelně a v každé takové iteraci se použijí jiné registry); tento způsob však vede k výraznému nárůstu kódu.
IA-64 využívá druhého způsobu, ovšem nárůstu kódu zabraňuje pomocí mechanismu rotating registers. Jedná se vlastně o to, že v cyklu se místo "absolutních" čísel registrů používají pouze jakési offsety vzhledem k bázi, která je uložena v Register Rotation Base registru (RRB). Hodnota tohoto registru se vždy po každé rotaci dekrementuje (tato rotace se provádí několikrát během jednoho průchodu cyklem, aby mohl být v paralelně prováděném následujícím průchodu cyklem použit registr se stejným offsetem vzhledem k RRB). To se projeví v jedné iteraci cyklu následovně: je-li hodnota A uložena v nějakém registru X, pak po jedné rotaci bude tato hodnota v registru X+1. Je-li X nejvyšší hodnota např. general-purpose registru (tj. GR127), pak po jedné rotaci se bude hodnota A nacházet v registru GR32.
Rotující registry jsou general-purpose registry (GR32-GR127), floating-point registry (FR32-FR127) a predikátové registry (PR16-PR63). Hodnota RRB (pro každý typ registrů existuje jeden RRB, tj. RRB.GR, RRB.FR, RRB.PR) je uložena v registru CFM.
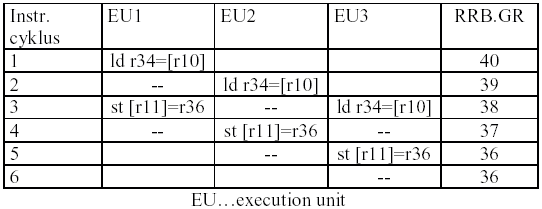
Př: uvažujme jednoduchý cyklus (v kódu značí "rXX" registr GRXX):
loop:
ld4 r34=[r10],4 ;load 4B into "r34", addr is stored in r10
st4 [r11]=r36,4 ;store from previous "r34" to addr stored in r11
br.ctop loop ;decrement loop counter and branch
Pozn. "r34" značí pouze offset, ve skutečnosti (pokud by rrb.gr=40) se může jednat o registr GR74.
Zde je příklad paralelního provádění tohoto cyklu (uvažujeme dobu load/store 2 instrukční cykly):
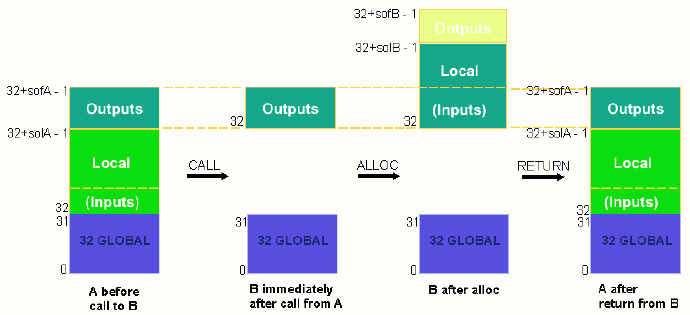
Register stack: Základním problémem starších architektur je to, že při skoku do podprogramu a návratu z něj je třeba: - uložit hodnoty registrů využívaných volajícím podprogramem a nastavit hodnoty registrů využívaných volaným podprogramem - předat parametry volanému podprogramu přes registry (nebo v horším případě přes stack) - což vede k další nutnosti uložení jejich hodnoty někam do paměti.
IA-64 implementuje mechanismus, který umožňuje se podobným problémům vyhnout - register stack. Jako register stack jsou označovány registry GR32-GR127. V této oblasti má každý podprogram (procedura) oblast registrů vyhrazenou pouze pro sebe (ta se nazývá stack frame a může zhrnovat 0 až 96 registrů). Toho se dosahuje opět pomocí přejmenování registrů. Důležitým faktem je to, že register stack se navenek chová jako neomezený (tj. skutečně jako zásobník registrů) - v případě, že systém nemá dostatek registrů GR v register stacku pro volaný podprogram, uloží celý register stack na zásobník do hlavní paměti, čímž dojde k jeho uvolnění. Tento mechanismus je zajišťován hardwarově pomocí Register stack engine (RSE) a z hlediska softwaru je plně transparentní.
Stack frame je obecně rozdělen na 2 části. Část lokálních dat a část výstupních dat. Pokud procedura A zavolá proceduru B, pak stack frame procedury B se inicializuje tak, že je tvořen pouze částí lokálních dat, která se ztotožní s výstupní částí stack framu procedury A (tak, že jí překryje) - tím se snadno mohou předávat parametry z volající procedury do volané. Potřebné místo (tj. velikost stack framu a jeho částí) procedury B se pak alokuje pomocí instrukce alloc (která se volá jako první instrukce každé procedury). Situace Register stacku při volání procedury B procedurou A je znázorněna na obrázku:
Instrukce LOAD: Tyto instrukce přenášejí data do general-purpose a floating-point registrů a případně i do dvojice floating-point registrů (floating-point pair).
V případě general register loads lze přenášet data o velikosti 1, 2, 4, 8 bytů. Pokud se přenáší méně než 8B, pak se zbytek doplní nulami.
Jedná-li se o floating-point load, jsou přenášeny 4B pro single precision, 8B pro single precision pair, 8B pro double precision, 16B pro double precision pair a 10B pro double-extended precision.
Instrukce STORE: Instrukce opačné k LOAD. Tzn. zajišťuje přenos dat z general-purpose a floating-point registrů do paměti. Neexistuje však pro dvojce floating-point registrů. Lze ukládat bloky dat o stejné velikosti, jako u instrukcí LOAD (až na single a double precision pair).
Všechny STORE instrukce jsou nespekulativní.
Spekulace: Jedná se o techniku, která umožňuje zbavit se prostojů zbůsobených čekáním při čtení dat z paměti.
Pokud je pravděpodobné, že se bude nějaká operace provádět a zároveň její provedení dopředu znamená umožnění dalšího paralelního provádění, provede ji procesor již dopředu.
Každá instrukce, která ukládá své výsledky do general nebo floating-point registrů je spekulativní. Naproti tomu instrukce, která modifikuje jiné než tyto registry je nespekulativní.
V IA64 jsou implementovány dva druhy spekulací. Jedná se o řídící a datovou spekulaci.
Řídící spekulace: Jedná se optimalizaci, kdy je instrukce, popř. sekvence instrukcí provedena dříve, než dynamický běh programu dosáhne místa, kde je výsledek těchto operací potřeba. Tato optimalizace má význam především u těch instrukcí, jejichž provádění trvá déle (např. load instructions). Samozřejmě zbytek programu je prováděn paralelně, a tak lze dosáhnout toho, že v době, kdy program dosáhne místa, kde by se měla daná instrukce reálně volat, je znám již výsledek jejího spekulativního provedení, kterého lze využít. Základní podmínkou pro použití spekulativního provádění je to, že v případě, kdy spekulativně prováděná instrukce vyvolá výjimku, pak se tato výjimka pozdrží (deferred exception) a tento chybný stav se vyznačí v cílovém registru (target register). Je-li to general registr, pak se nastaví NaT bit na "1", je-li to floating-point registr, pak se do něj uloží hodnota NaTVal.
Důvodem pro pozdržení vyvolané výjimky je fakt, že v případě kdy nejsou výsledky spekulativně provedených instrukcí potřeba (tj. program se nedostal do toho bodu, kde se mají výsledky spekulativního provedení uplatnit) se výsledky tohoto provádění jednoduše zruší (a s nimi i výjimka, která se ve skutečnosti neměla vůbec vyvolat). Pokud se však program dostane na místo, kde se mají uplatnit výsledky spekulativního provádění, provede se jejich kontrola a v případě, že spekulativně provedená instrukce vyvolala výjimku, je nutné tuto výjimku ošetřit (to vede zpravidla na znovu provedení této instrukce, tentokrát však nespekulativně). Control speculation se provádí tak, že spekulativní instrukce (např. ld.s) se umístí v kódu někam před původní instrukci (zde ld) a na toto místo se umístí instrukce kontroly výsledku spekulativního provedení (chk.s). Tato instrukce zároveň indikuje, že výsledky spekulativního provedení jsou požadovány. Doteď jsme uvažovali, že se spekulativně provádí pouze jedna instrukce. Výsledky této instrukce (spekulativní) se mohou použít pro další spekulativní provádění. V případě, že první spekulativní instrukce vyvolá výjimku, pak též druhá instrukce by měla indikovat výjimečný stav, neboť vstupní data pro tuto instrukci nebyla správná. To se provádí propagací tzv. exception token (ten indikuje výjimku ve výsledku spekulativní instrukce). Tato propagace se projeví tak, že instrukce využívající data jiné spekulativní instrukce (která vyvolala výjimku) bude mít nastaven NaT nebo bude mít hodnotu NaTVal. Control speculation se zpravidla aplikuje na instrukce v různých větvích programu, které jsou pak spekulativně provedeny ještě před místem příslušného větvení.
Datová spekulace: Tato optimalizace umožňuje spekulativně provádět instrukce, jejichž operandy mohou být závislé na výsledku jiných (nespekulativních) instrukcí (takovéto závislosti mezi instrukcemi jsou v originále označovány jako data dependencies). Typickou ukázkou použití data speculation je následující příklad, kdy instrukce store předchází instrukci load (kterou chceme spekulativně provést).
Pozn. V případě data speculation nemají spekulativně prováděné instrukce označení speculative (např. ld.s), ale advanced (např. ld.a).
Př: /*původní kód*/ /*kód se spekulativním prováděním*/
… …
store(source, addr1) advanced load(addr2, target)
load(addr2, target) …
use(target) store(source, addr1)
… check for advanced load
use(target)
…
Provedení instrukce load před inst. store nebrání nic, pokud adresové prostory přistupované těmito instrukcemi nemají žádný průnik. V opačném případě nelze tyto instrukce zaměnit (fyzicky), a proto je nutné provést tuto záměnu "spekulativně". Otázkou však je, jak poznat, že výsledky operace load jsou závislé na operaci store, která teprve následuje? K tomu se používá speciální tabulky, která je organizována jako pole registrů (register file) - ALAT (advanced load address table). Pokud spekulativně prováděná instrukce load čte data z adresy addr1, pak se z této adresy odvodí (vypočítá) index do tabulky ALAT, kam uloží tuto adresu. Následující instrukce store pak (to se provádí ve fázi DET) zkontroluje zda v ALAT není platný záznam na místě, které je určeno adresou, na kterou tato instrukce ukládá data. Pokud je takový záznam nalezen, dojde k jeho odstranění. Následující instrukce (ld.c nebo chk.a) pro kontrolu spekulativně provedené instrukce prohlídne příslušnou položku v ALAT - pokud není nalezen platný záznam, je výsledek spekulativní instrukce neplatný (díky data dependency) a instrukci load je třeba provést znovu. V případě, kdy dojte při spekulativním provádění k výjimce, je tato obsloužena okamžitě, tj. v případě data specualtion tedy nedochází k pozdržení výjimek (v porovnání s control speculation). V případě Mercedu, je ALAT 32-položková a lze jí indexovat pomocí 7-bitového registru ID. Index do tabulky se určuje pouze z části adresy, se kterou pracuje spekulativní instrukce. To může způsobovat kolize a výsledkem jsou chybné záznamy v tabulce. Nicméně důsledky těchto kolizí nejsou nikterak závažné - je pouze třeba provést instrukci (která byla spekulativně provedena dříve) znova.
Závěr: Tento high-end procesor od Intela našel své uplatnění v oblasti serverů.
V současné době již Intel prodává Itanium2, které běží na frekvenci jen o málo vyšší (1GHz) a přesto udajně dosahuje zlepšení výkonu o 50 až 100% díky vylepšené architektuře.